Sorting Queries with AWS Amplify's Key Directive
In this tutorial, you are going to learn how to sort your GraphQL queries in AWS Amplify using the @key directive.
Note: This article is a tutorial for intermediates. Do you want to learn how to accelerate the creation of your projects using Amplify 🚀? For beginners, I recommend checking out Nader Dabit's free course on egghead, or Amplify's 'Getting Started' to learn the basics.
The AWS Amplify GraphQL Transform toolchain exposes the @key directive which lets you define custom index structures. In other words, you can sort the data in your queries with it. This is useful if you have queries that you want to sort on the server side instead of the client side. We will look at an example with pagination.
DynamoDB
To understand the @key directive, you need to know how DynamoDB saves data - specifically primary keys and secondary indexes 🧐. Like other databases, DynamoDB stores data in tables. The docs give an excellent summary.
A table is a collection of items, and each item is a collection of attributes. DynamoDB uses primary keys to uniquely identify each item in a table and secondary indexes to provide more querying flexibility."
Other than the primary key, tables are schemaless and different items in the same table can have different attributes.
Each attribute can either be a scalar or a nested attribute. A scalar is a primitive value such as a string or a number. An attribute is nested, if it has attributes itself. E.g. if a Song has a Genre, which has a Name, which is a string, Genre would be a nested attribute.
{
"SongId": 1,
"Artist": "Deadmau5",
"Title": "Strobe",
"Genre": {
"Name": "House"
},
"Key": "B maj"
}In the example above, SongId is the primary key which uniquely identifies the item in the table.
But you could also leave it out, if you choose to identify the song by Title and Artist and these two attributes together make up the primary key.
{
"Artist": "Deadmau5",
"Title": "Strobe",
"Genre": {
"Name": "House"
},
"Key": "B maj"
}The downside is that using Artist and Title there couldn't be two songs from the same artist with the same title.
Primary keys 🥇
When you create a table in DynamoDB, you have to specify how you want to identify the items in the table.
If you use a single attribute like SongId, it is called a partition key. The name originates from the fact that the partition key is used in an internal hash function to determine the physical storage internal to DynamoDB by evenly distributing data items across partitions. Therefore, the partition key is sometimes referred to as the primary index’s hash key. Now it makes sense that the primary key has to be unique, doesn't it?
If you use two attributes like Artist and Title, you are using composite primary keys. The first attribute is the partition key, and the second attribute is the sort key. Just like with one key, the partition key determines the physical location. Using composite primary keys, items with the same partition key are stored together, but they can be distinguished because they are sorted in order by the sort key. Sort keys are sometimes referred to as the range key.
Secondary Indexes 🥈
Optionally, you can add secondary indexes to your tables, which let you do queries against other attributes in addition to the primary key. The table which the secondary index is associated with is called the base table.
There are two types of secondary indexes: global and local. Global secondary indexes have both a different partition key and a different sort key from the base table, while secondary indexes have the same partition key, but a different sort key. Their naming comes from the fact that global indexes can query data across all partitions, whereas local indexes are scoped to it's partition key. It follows that local secondary indexes must always be composite.
In conclusion, using secondary indexes, you could also query the songs by Key even though its not part of the primary index.
Note that the attributes for composite keys for both primary keys and secondary indexes must always be top-level attributes of type string, number, or binary.
@key
We have the basics down. Let's examine AWS Amplify's @key directive. You can add @key to @model directives. Each @model generates a table. Using @key, we can either overwrite its primary key or add secondary indexes. The former you can only do once for each @model, while DynamoDB's limits limit the ladder.
We are going to look at a contact list example. Let's define our model without the @key directive.
type Contact @model {
id: ID!
lastName: String!
firstName: String!
age: Int!
}Now we can query for distinct users by using the getContact query, where id is the respective contact's UUID.
const data = await API.graphql(graphqlOperation(getContact, { id }));
const listData = await API.graphql(graphqlOperation(listContacts));Note that in this example we assume id to be defined and pass it to graphqlOperation using the object shorthand notation. The listContacts query can be used like this without any additional arguments for each schema that we'll define below. What changes is the behaviour of the get queries and the list queries with arguments.
Behind the scenes, AWS Amplify created a table for the contact scheme where id is the partition key, which is why we can provide it as an argument to the getContact query.
Now, instead of auto-generating the partition key to be the id, we can also set it manually using the @key directive.
Note: In the following, if you would also specify an id field, you would have to populate that id yourself. Also, note that changing the partition key might require you to rename your table or to create a new table.
CloudFormation cannot update a stack when a custom-named resource requires replacing. Rename Contact-26hrt3bw6nas5lrnshsoilftha-master and update the stack again.type Contact @model @key(fields: ["lastName"]) {
lastName: String!
firstName: String!
age: Int!
}This enables us to query by lastName instead of by id. Since we omitted @key's name argument lastName is now the primary key.
const data = await API.graphql(
graphqlOperation(getContact, { lastName })
);But this schema would prohibit two contacts with the same last name. Let's use a composite primary key instead to identify by firstName and lastName uniquely. We'll pick lastName as the partition key and firstName as the sort key.
type Contact @model @key(fields: ["lastName", "firstName"]) {
lastName: String!
firstName: String!
age: Int!
}We have to take the composite key into account when querying for contacts.
const data = await API.graphql(
graphqlOperation(getContact, { lastName, firstName })
);This results in responses being sorted by lastName and then by firstName.
We can take it even further. What if we also wanted to sort and query the contacts by age? Just add it to the @key field.
type Contact @model @key(fields: ["lastName", "firstName", "age"]) {
lastName: String!
firstName: String!
age: Int!
}The get query stays more or less the same; you merely need to add age.
const data = await API.graphql(
graphqlOperation(getContact, { firstName, lastName, age })
);If you left out age or any other attribute, you would get an error.
"Variable 'age' has coerced Null value for NonNull type 'Int!'If you want to do list query now, your first instinct might be to stick age alongside lastName and firstName into graphqlOperation, but that won't work because DynamoDB limits queries to two attributes. If you use @key with more than two attributes, the first becomes the partition key (as always), and the sort key will be a composite key made of the rest of the attributes. The new sort key is named by camel casing and adding the attributes used. In our case, we get firstNameAge. This change is reflected in the list query.
const listData = await API.graphql(
graphqlOperation(listContacts, {
lastName: 'Hesters',
firstNameAge: {
beginsWith: { firstName, age: 2 },
},
})
);This will list all contacts with the given last name, whose first name starts with firstName and whose age starts with a 2 (2, 23, 27, 215 etc.).
You can still filter queries.
const listData = await API.graphql(
graphqlOperation(listContacts, {
lastName: 'Hesters',
filter: { firstName: { eq: firstName } },
})
);And you can even combine querying using the sort key with filtering.
const listData = await API.graphql(
graphqlOperation(listContacts, {
lastName: 'Hesters',
filter: { age: { eq: 25 } },
firstNameAge: {
beginsWith: { firstName, age: 2 },
},
})
);Obviously, the query above doesn't make much sense because you filter for age "equal to 25" and "begins with 2", but "equal to 25" is the stronger restriction and renders "begins with 2" useless. I just wanted to show you that it's possible.
Lastly, if you give @key a name and a queryField value, you automatically use secondary indexes instead of primary keys.
type Contact
@model
@key(
name: "ByName"
fields: ["lastName", "firstName"]
queryField: "contactsByName"
) {
id: ID!
lastName: String!
firstName: String!
age: Int!
}This generates a new list query called contactsByName. Amplify still sets up the old listContacts query. We generated a global secondary index. To generate a local secondary index, you would have to set up a composite primary key and generate a secondary index with the same partition key as your primary key.
const data = await API.graphql(
graphqlOperation(contactsByName, { lastName })
);The new query filters all contacts by the given last name and then sorts them by last name and first name.
Example
Let's use the @key directive in an example. I want to try out the new Expo SDK with Hooks, so let's use Expo to create a React Native app.
expo initChoose blank, cd into your app's directory and add Amplify.
amplify init
amplify add apiChoose Amazon Cognito User Pool as your way of authentication and add the following schema.
type Contact
@model
@key(
name: "ByOwnerLastNameFirstName"
fields: ["owner", "lastName", "firstName"]
queryField: "contactsByOwner"
)
@auth(rules: [{ allow: owner }]) {
id: ID!
firstName: String
lastName: String
age: Int
owner: String
}Using the Cognito console create an account and use it to create four contacts via the AWS AppSync console.
mutation create {
createContact(
input: { firstName: "Alice", lastName: "Zebra", age: 30 }
) {
firstName
lastName
age
}
}These are the four contacts I created.
[
{ "firstName": "Bob", "lastName": "Zebra", "age": 30 }
{ "firstName": "Caitlin", "lastName": "Springsteen", "age": 66 },
{ "firstName": "Alice", "lastName": "Zebra", "age": 30 },
{ "firstName": "Jan", "lastName": "Hesters", "age": 25 },
]Install React Native Elements and React Navigation to make it look pretty as well as AWS Amplify for the helper functions.
yarn add react-native-elements react-navigation aws-amplifyNow we are going to fetch the users using contactsByOwner, which will automatically sort them by their firstName and lastName attribute.
import React, { useEffect, useState } from 'react';
import { StyleSheet } from 'react-native';
import {
createAppContainer,
createStackNavigator,
SafeAreaView,
} from 'react-navigation';
import { ListItem, Button } from 'react-native-elements';
import Amplify, { API, graphqlOperation, Auth } from 'aws-amplify';
import { contactsByOwner } from './src/graphql/queries';
import config from './aws-exports';
Amplify.configure(config);
function App() {
useEffect(() => {
async function login() {
try {
await Auth.signIn('key@tutorial.com', 'password');
} catch (error) {
console.log(error);
}
}
login();
}, []);
const [contacts, setContacts] = useState([]);
const [nextToken, setNextToken] = useState(null);
const [loading, setLoading] = useState(false);
async function fetchContacts() {
setLoading(true);
try {
const { username: owner } = await Auth.currentAuthenticatedUser();
const data = await API.graphql(
graphqlOperation(contactsByOwner, { limit: 3, nextToken, owner })
);
setContacts([...contacts, ...data.data.contactsByOwner.items]);
setNextToken(data.data.contactsByOwner.nextToken);
} catch (error) {
console.log(error);
} finally {
setLoading(false);
}
}
const buttonProps =
contacts.length === 0
? { title: 'Fetch Contacts' }
: nextToken
? { title: 'Fetch More Contacts' }
: { title: 'All Contacts Fetched', disabled: true };
return (
<SafeAreaView style={styles.container}>
{contacts.map(({ id, firstName, lastName, age }) => (
<ListItem
key={id}
title={`${firstName} ${lastName}`}
subtitle={age.toString()}
/>
))}
<Button
disabled={loading}
onPress={fetchContacts}
loading={loading}
{...buttonProps}
/>
</SafeAreaView>
);
}
App.navigationOptions = {
title: 'Contacts',
};
const styles = StyleSheet.create({
container: {
flex: 1,
padding: 7,
},
});
export default createAppContainer(
createStackNavigator({ ContactsScreen: App })
);This code is pretty straightforward. First, we configure Amplify. Afterwards, we log us in with the user that we created in a useEffect Hook. Next, we use useState to save the fetched contacts, the queries nextToken and a loading boolean that indicates whether a GraphQL request is happening. fetchContacts sets the loading boolean to true while fetching. And it loads the contacts using the contactsByOwner query after getting the owner's id. The buttonProps object gets a title depending on the nextToken and the contacts fetched, and disables the button if there are no more contacts. Lastly, we map over the contacts and render them in a ListItem along with a Button, which calls fetchContacts when pressed. We also wrap everything in a stack navigator to get a proper header.
Here is how the app looks.
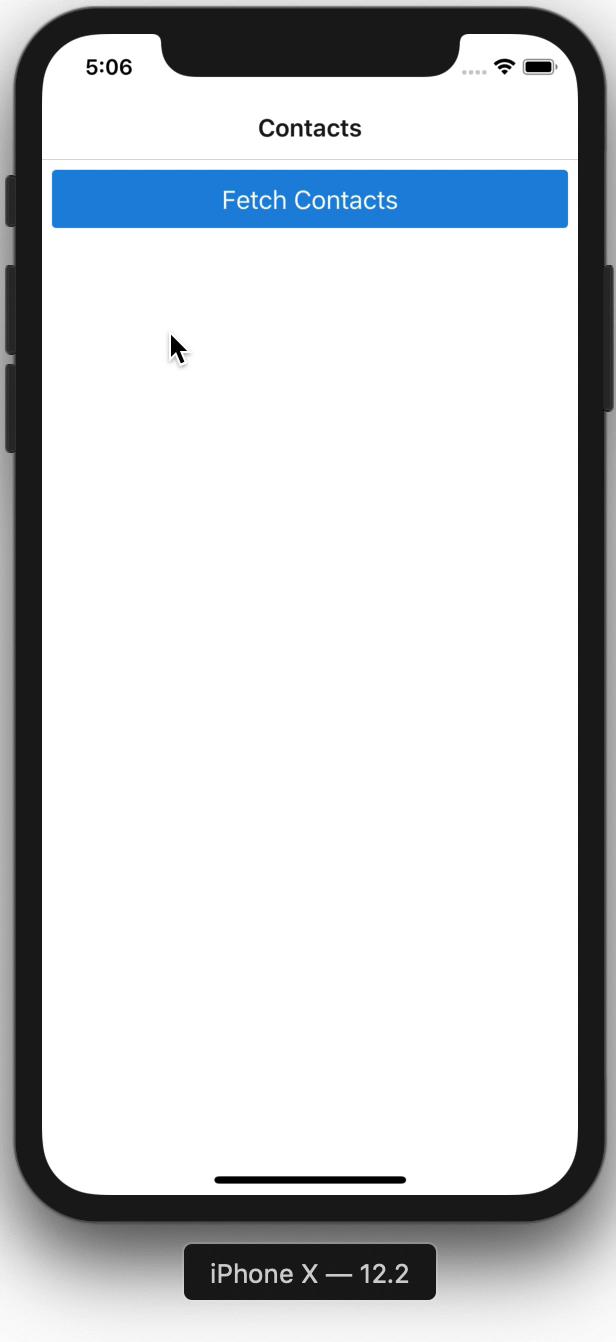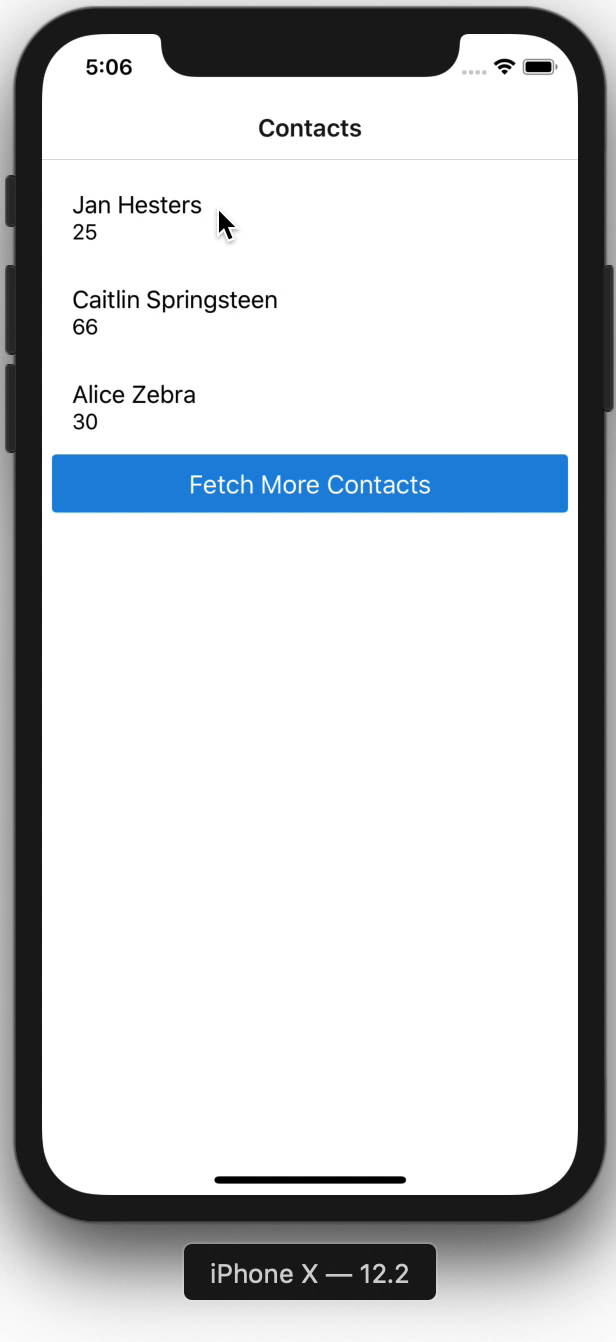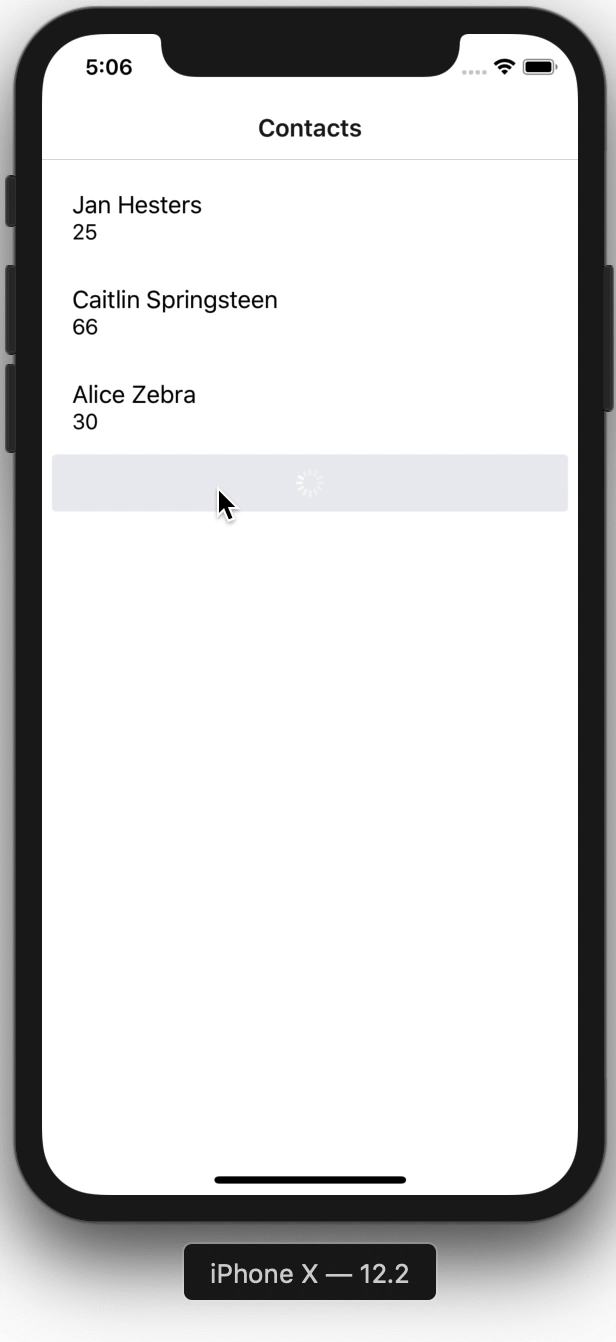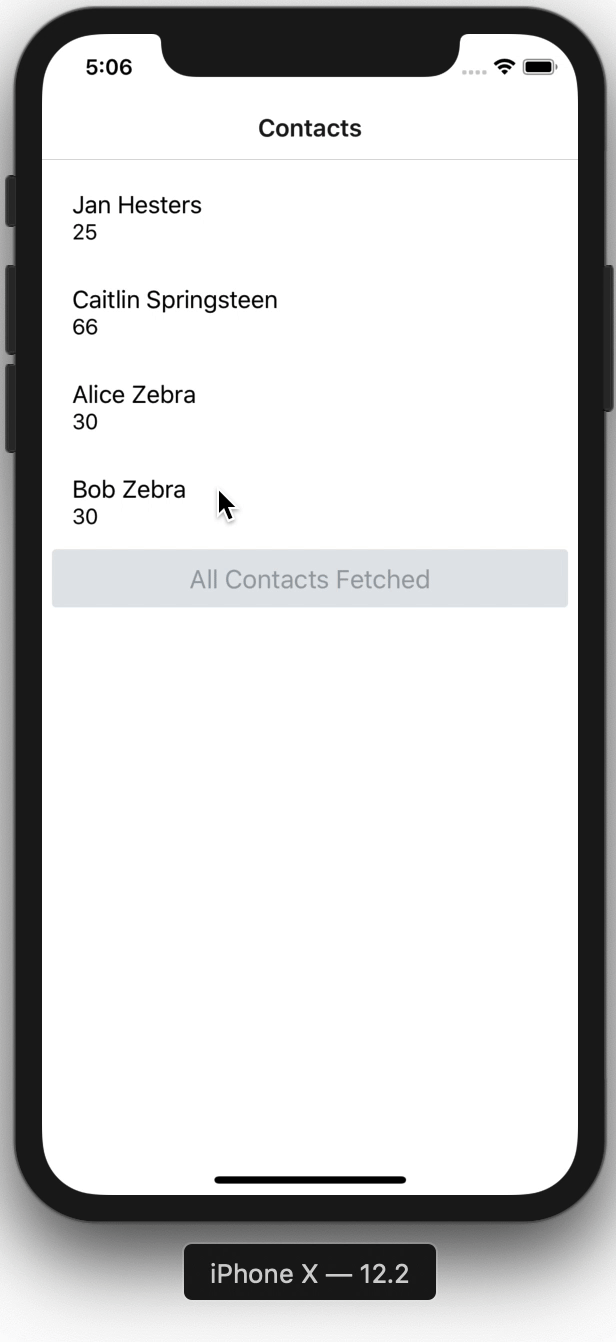
That's how easy sorting with the @key directive is.
If you liked this article you might also like "Tracking and Reminders in AWS Amplify" in which we set up tracking in an AWS Amplify app.
Summary
We looked at how DynamoDB saves data and how the @key directive influences the items' keys and indexes. Afterwards, we coded up an example utilizing the @key directive to sort our data in the query.